Google发布Open Images V6:极大扩展数据集注释
近日,Google AI 宣布发布 Open Images V6,和 V5 版本相比,它极大地扩展了 Open Images 数据集的注释,增加了大量新的视觉关系(例如,“狗抓飞盘”)、人类动作注释(例如,“女人跳跃”)和水平图像标签(例如,“paisley”)。
值得注意的是,该版本还添加了本地化叙述,这是一种全新的多模态注释形式,由同步的语音、文本和鼠标跟踪所描述的对象组成。在 OpenImagesV6 中,这些本地化的叙述可用于 500k 图像。此外,为了便于与之前的工作进行比较,Google 还为 COCO 数据集的全部 123k 图像发布了本地化的叙述注释。
Open Images V6 网址:https://g.co/dataset/openimages
COCO 数据集网址:http://cocodataset.org/

Open Images V5 中的注释模式:水平图像标签、边界框、实例分段和视觉关系。图片来源:1969 年 D.Miller 的 Camaro RS/SS、anita kluska 的 the house、Ari Helminen 的 Cat Cafe Shinjuku calico、Andrea Sartorati 的 Radiofiera-Villa CorDELLina Lombardi、Montecchio Maggiore(VI)-agosto 2010。
从很多方面来讲,Open Images 是最大的带注释图像数据集,用来训练用于计算机视觉任务的最新深度卷积神经网络。
视频网址:https://youtu.be/mZqHVUstmIQ

本地化叙述
本地化叙述背后的动机之一是研究、利用视觉和语言之间的联系,通常是通过图像字幕加上人的文本描述完成。然而,图像字幕的局限性之一是缺乏视觉基础,即我们不知道文本描述的是图像中的哪一块。为了减轻这一问题,以前的一些数据集对文本描述中出现的名词画了一个后验框。相反,在本地化的叙述中,文本描述的每个词都是有对应位置的。

图像内容和字幕之间的不同层次的对应。从左到右:整个图像的标题(COCO);矩形框的名词(Flickr30k 实体);鼠标跟踪段的每个单词(本地化叙述)。图片来源:COCO,Flickr30k Entities,和 Rama 的 Sapa。
本地化的叙述是由注释者生成的,他们提供图像的口头描述,同时将鼠标悬停在所描述的区域上。语音注释是其方法的核心,它直接将描述与其所引用的图像区域连接起来。为了使描述更易于访问,注释者将自动语音转录结果与手动转录结果对齐。这恢复了描述的时间戳,确保语音、文本和鼠标跟踪这三种模式正确且同步。
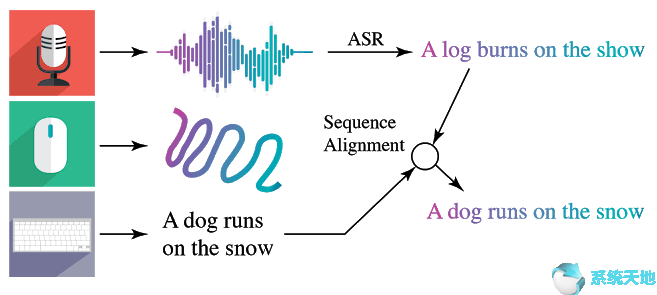
手动和自动转录的对齐,图像是基于 Freepik 的原创作品设计的。
在说话的同时进行指示是非常直观的,为研究人们描述图像创造了更多方法。例如,我们观察到,在表示对象的空间范围时有不同风格的线条——环绕、划满线条、下划线等等——对这些风格的研究可以为新用户界面的设计带来有价值的见解。

鼠标跟踪与图像下面的单词对应的区域。图片来源:Via Guglielmo Marconi,Elliott Brown 的 Positano-Hotel Le Agavi-boat,vivek jena的air frame,以及弗吉尼亚州立公园的 CL P1050512。
这些本地化的叙述所代表的额外数据量到底有多大?据了解,鼠标轨迹的总长度约为 6400 公里,如果不停地朗读,所有的叙述将需要约 1.5 年的时间读完!
新的视觉关系、人类行为和水平图像注释
除了本地化的叙述之外,在 OpenImagesV6 中,Google 将视觉关系注释的类型增加了一个数量级(高达 1.4K),例如添加了“男人滑滑板”、“男人和女人牵着手”和“狗抓飞盘”等。

自从计算机视觉诞生以来,图像中的人就一直是其研究的核心领域之一,理解这些人在做什么对许多应用来说至关重要。因此,Open Images V6 还包含了 250 万个人类执行独立动作的注释,比如跳跃、微笑或躺下。

最后,Google 还添加了 2350 万个新的人工验证的水平图像标签,有接近 20000 个类别,大小超过 59.9M。
Open Images 挑战赛
在去年 5 月发布的第 5 版 Open Images V5 中包含 9M 图像,并有 36M 的水平图像标签、15.8M 的边界框、2.8M 的分段实例和 391k 的视觉关系。
与数据集本身一样,2019 年 Google举办了 Open Images 挑战赛,比赛分为目标检测、实例分割和视觉关系检测三个赛道,对这三个方向技术的最新进展起到了积极的推动作用。
大赛介绍
目标检测赛道
目标检测赛道要求预测对象实例周围的边界框。
训练集包含 12.2M 的边界框,跨越 500 个类别,覆盖 170 万张图片。为了确保准确性和一致性,这些边界框大部分是由专业注释员手工绘制的。数据集图像非常多样化,通常包含多个对象的复杂场景——平均每张图像有 7 个对象。
比赛网址:https://www.kaggle.com/c/open-images-2019-object-detection
实例分割赛道
实例分割赛道要求提供对象的分段掩码。
训练集包含 300 个类别中 2.1M 分段实例掩码;验证集包含额外的 23k 掩码。训练集掩码是由最先进的交互式分割过程产生的,在这个过程中,专业的人类注释者迭代地校正分割神经网络的输出。为保证质量,验证和测试集掩码是手动注释的。

比赛网址:https://www.kaggle.com/c/open-images-2019-instance-segmentation
视觉关系检测赛道
视觉关系检测赛道要求检测对象对以及连接它们的关系。
训练集包含 329 个关系(三对三)和 375k 训练样本。这些关系既包括人与物的关系(例如“女人弹吉他”、“男人拿麦克风”),也包括物与物的关系(例如“桌子上的啤酒”、“车里的狗”),还包括物与物的属性关系(例如“手提包是皮革做的”和“长凳是木制的”)。

比赛网址:https://www.kaggle.com/c/open-images-2019-visual-relationship
大赛奖金
挑战赛的总奖金为 75,000 美元,在三个赛道之间平均分配。其中:
第一名:$ 7,000
第二名:$ 6,000
第三名:$ 5,000
第四名:$ 4,000
第五名-:$ 3000
Open Images V6 是改进图像分类、目标检测、视觉关系检测和实例分割的统一标注的一个重要的定性和定量步骤,它采用了一种新颖的方法将视觉和语言与局部叙述联系起来。Google 希望 Open Images V6 将进一步促进场景理解的研究进展。
via:https://ai.googleblog.com/2020/02/open-images-v6-now-featuring-localized.html
https://www.kaggle.com/c/open-images-2019-object-detection
https://storage.googleapis.com/openimages/web/challenge2019.html#instance_segmentation
https://www.kaggle.com/c/open-images-2019-visual-relationship